Immagine di Wonderlane/Flickr (CC BY 2.0)
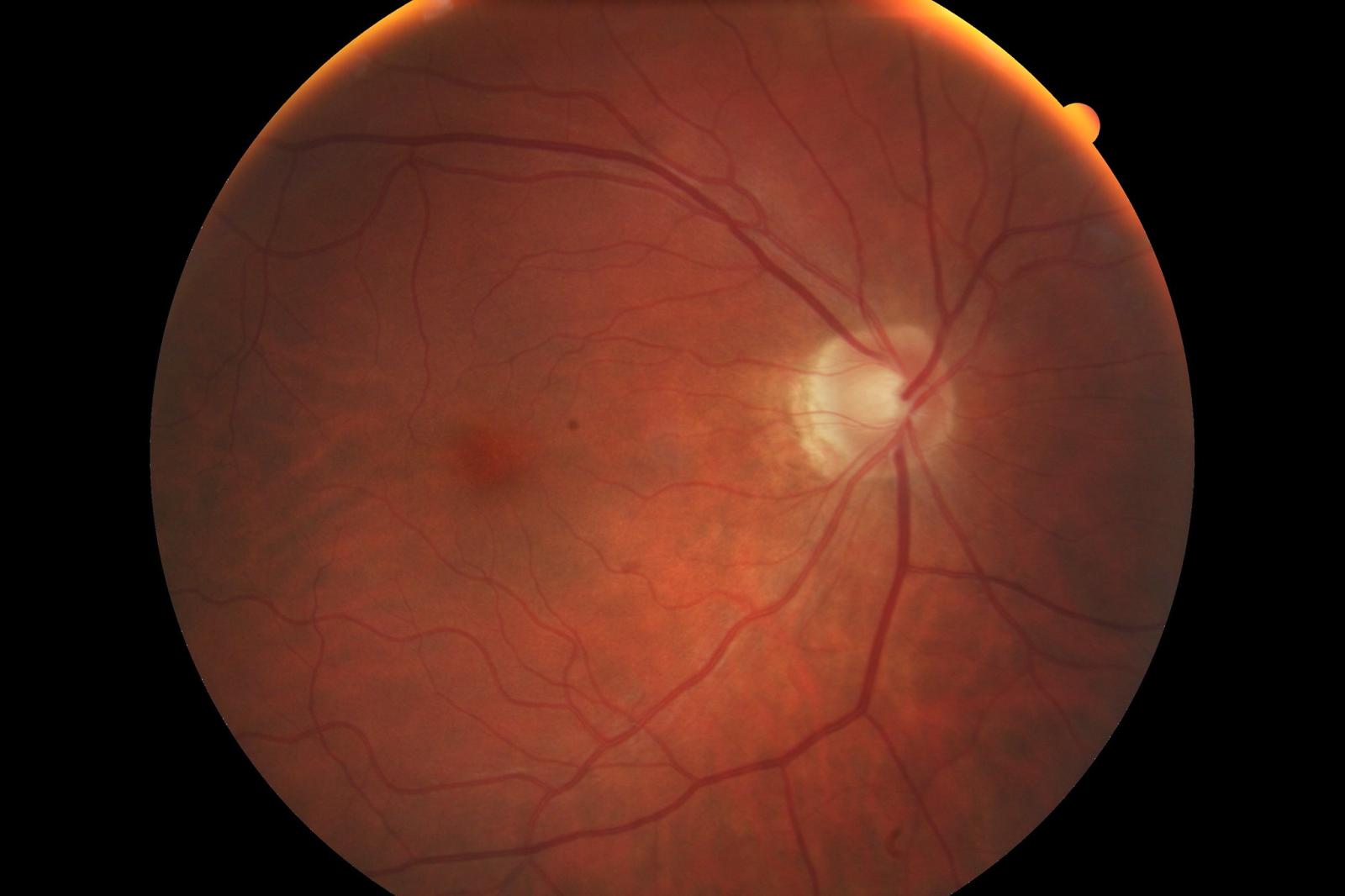
Un’intelligenza artificiale capace di dedurre la massa e il volume del ventricolo sinistro del cuore analizzando l’immagine della retina e da lì stabilire se il paziente è a rischio di andare incontro a un infarto del miocardio. È l’ultima applicazione in ambito medico di un sistema di deep learning pubblicata la scorsa settimana su Nature Machine Intelligence da un gruppo di matematici, informatici e cardiologi coordinati da Alejandro Frangi, professore di medicina computazionale alla University of Leeds e dal 2019 membro del comitato per le tecnologie emergenti della Royal Academy of Engineering, e Andres Diaz-Pinto, ricercatore al King’s College London.
Ogni anno in Europa a 11 milioni di persone viene diagnosticata una tra le malattie cardiovascolari, che restano la prima causa di morte nel continente. Circa il 45% del totale dei decessi annuali può essere attribuito a una malattia cardiovascolare, per un totale di 3,8 milioni di morti all’anno. Tra i maggiori fattori di rischio sono stati identificati obesità, dipendenza da fumo e alcol, diabete, ipertensione. Ma il monitoraggio e la prevenzione di queste patologie richiede spesso l’intervento di medici specializzati in cardiologia. Per questo, la possibilità di sfruttare le immagini raccolte dagli oculisti per indirizzare i pazienti verso ulteriori approfondimenti è particolarmente promettente.
Che l’analisi del fondo oculare fosse capace di dare informazioni preziose sullo stato di salute del sistema cardiovascolare era già stato indicato da diversi studi negli ultimi vent’anni. La morfologia e la dimensione dei piccoli vasi sanguigni della retina sono indicatori di malattie vascolari più ampie, comprese le patologie cardiache. Nel 2018, i ricercatori di Google avevano messo a punto una rete neurale profonda, più precisamente una convolutional neural network (CNN), per dedurre a partire dalle immagini dei fondi oculari i principali fattori di rischio delle malattie cardiovascolari, come età, sesso, fumatore/non fumatore, pressione sistolica (massima) e anche l’insorgenza di infarto o ictus nei 5 anni successivi. L’algoritmo era stato sviluppato e testato su diversi database, tra cui quello della UK Biobank, mostrando che l’algoritmo era capace di prevedere l’insorgenza di un evento cardiovascolare maggiore (ictus o infarto) con un’accuratezza di poco inferiore ai sistemi di valutazione del rischio cardiovascolare che si basano solo sulla conoscenza dei fattori di rischio.
Il gruppo di scienziati coordinati da Frangi ha fatto un passo in più, sfruttando anche le informazioni contenute nelle immagini raccolte tramite risonanza magnetica cardiaca. Questo è stato possibile grazie a un particolare tipo di sistema di deep learning, chiamato multi-channel variational autoencoder (mcVAE), che è stato allenato per mettere in relazione le immagini della retina e quelle delle risonanze magnetiche cardiache in un gruppo di circa 5600 partecipanti alla UK Biobank per cui entrambi i tipi di immagine erano disponibili. Il sistema è stato poi sfruttato per dedurre le immagini cardiache a partire dai fondi oculari per quei pazienti per cui le immagini cardiache non erano disponibili. A sviluppare il sofisticato algoritmo è stato il matematico e informatico italiano Marco Lorenzi, ricercatore presso il centro Sophia Antipolis dell’Institut National de recherche en informatique et en automatique (INRIA) in Francia.
Le immagini cardiache ricostruite a partire da quelle della retina sono state poi corredate da una serie di informazioni demografiche (età, sesso, consumo di alcol, stato di fumatore, pressione sanguigna, livello di glucosio e di colesterolo) per stimare, attraverso un secondo sistema di deep learning, la massa e il volume del ventricolo sinistro del cuore, due parametri rilevanti al fine di prevedere l’insorgenza di un infarto del miocardio. Le stime ottenute si sono rivelate in ottimo accordo con quelle effettuate da un gruppo di otto esperti che hanno analizzato le immagini di risonanza magnetica cardiaca con il miglior software disponibile sul mercato.
I ricercatori hanno poi sviluppato un terzo algoritmo, questa volta un “semplice” sistema di regressione lineare, per stabilire quali pazienti sarebbero andati incontro a un infarto del miocardio sulla base delle stime di massa e volume del loro ventricolo sinistro e delle loro caratteristiche demografiche. Per farlo hanno sfruttato un secondo database, sempre estratto dalla UK Biobank, contenente i dati di circa 2000 persone per cui erano disponibili solo le immagini del fondo oculare, oltre alle solite informazioni demografiche. Non era infatti necessario avere le immagini della risonanza magnetica cardiaca, perché il primo algoritmo è stato incaricato di ricostruirle a partire dalle immagini della retina. Di queste 2000 persone, metà avevano sofferto di infarto dopo aver scattato l’immagine del fondo oculare e l’altra metà no. Gli autori hanno usato una parte di questo campione per allenare il loro algoritmo e la restante parte per valutarne i risultati. In media, la sensibilità e la specificità dell’intero sistema sono del 74% e 71% rispettivamente, mentre la sua precisione è del 73%. In questo caso, la sensibilità è la frazione di persone che il sistema ha previsto sarebbero andate incontro a un infarto tra coloro che lo hanno poi effettivamente avuto. La specificità è invece la frazione di persone che il sistema ha previsto non sarebbero andate incontro a un infarto tra coloro che non lo hanno effettivamente avuto. Infine, la precisione è la frazione di persone che hanno effettivamente avuto un infarto tra coloro che il sistema ha previsto lo avrebbero avuto.
Per fare una valutazione realistica, i ricercatori hanno ripetuto tutta l’analisi usando solo i dati demografici che sono di solito disponibili in uno studio oculistico, età e sesso, osservando una lieve diminuzione della precisione dell’algoritmo, dal 73% al 68%, mentre la sensibilità è rimasta invariata, pari al 74%, e la specificità è aumentata al 73%. Questi risultati vanno confrontati con i più diffusi modelli per la valutazione del rischio di sviluppare patologie cardiovascolari, che si basano solo sulle caratteristiche demografiche dei pazienti. Un confronto vero e proprio non è possibile, perché questi modelli non sono mai stati usati sui dati della UK Biobank. Tuttavia, un’idea delle loro performance si può ottenere guardando a studi come quello realizzato nel 2019 sfruttando i dati raccolti dal progetto DETECT coordinato dalla Università tecnica di Dresda. Lo studio ha confrontato diversi modelli di valutazione del rischio cardiovascolare sul campione dei circa 4000 partecipanti del progetto DETECT, concludendo che la sensibilità variava tra 56% e 78%, la specificità tra 60% e 78% e la precisione tra 12% e 24%.
«Anche se le prestazioni del nostro approccio in questo studio non possono essere paragonate direttamente a quelle disponibili per gli altri modelli di valutazione del rischio, questi confronti evidenziano il suo potenziale come strumento per indicare la necessità di un approfondimento specialistico per i pazienti che si sottopongono a una visita oculistica», scrivono i ricercatori.
«Stiamo discutendo con i nostri partner clinici, tra cui il National Eye Institute di Bethesda e lo York Teaching Hospital, la possibilità di testare sul campo il nostro algoritmo», spiega Diaz-Pinto, «ma occorre considerare una serie di aspetti prima di avviare lo studio clinico».
Tra questi ne spiccano due per importanza. Il primo è la composizione demografica del gruppo su cui l’algoritmo verrà testato. Per esempio, l’etnia: il database della UK Biobank utilizzato dai ricercatori per sviluppare il loro sistema è composto al 90% da persone bianche, le altre provenienze geografiche sono scarsamente rappresentate, 1,2% neri e 3,4% asiatici. Le sue performance sono state valutate su quel database e non è detto che su un campione diversamente composto si confermino allo stesso livello. «I campioni di dati che contengono sia immagini del fondo oculare che risonanze magnetiche cardiache sono estremamente rari, quindi non è detto che sarà possibile adattare il nostro algoritmo a popolazioni diverse da quella che abbiamo considerato in questo studio», continua Diaz-Pinto.
Il secondo aspetto da tenere in considerazione è la disponibilità di immagini della retina di alta qualità, necessarie perché il primo algoritmo ricostruisca in maniera sufficientemente accurata l’immagine cardiaca.
Nel 2020, Google Health ha messo alla prova sul campo l’algoritmo di deep learning che aveva sviluppato quattro anni prima per la diagnosi della retinopatia diabetica, una patologia che, se non diagnosticata in tempo, può portare alla cecità. L’occasione per effettuare questo test è arrivata quando la Thailandia ha deciso di organizzare un programma di screening per questa patologia che raggiungesse almeno il 60% delle persone diabetiche nel paese. L’obiettivo si era presto rivelato irraggiungibile per via del numero limitato di specialisti in grado di effettuare i giusti esami diagnostici. Il governo thailandese ha aperto una collaborazione con Google equipaggiando undici ambulatori con il loro sistema di deep learning per permettere di analizzare in tempo reale le foto del fondo oculare scattate dagli infermieri, arruolati anch’essi nel progetto. Se nelle condizioni ideali dello studio scientifico l’algoritmo si era rilevato accurato al 90%, le cose sono andate molto diversamente nella realtà. Molte immagini non avevano qualità sufficiente e venivano rifiutate dal sistema, in altri casi la rete internet era lenta e bisognava aspettare ore per avere i risultati. «Nel nostro studio abbiamo un sistema automatico che seleziona le immagini in base alla loro qualità», spiega Diaz-Pinto, «è quindi cruciale valutare l’impatto di questo sistema di selezione in un dato contesto clinico prima di avviare lo studio».
Per ricevere questo contenuto in anteprima ogni settimana insieme a sei consigli di lettura iscriviti alla newsletter di Scienza in rete curata da Chiara Sabelli (ecco il link per l'iscrizione). Trovi qui il testo completo di questa settimana. Buona lettura, e buon fine settimana!
