Today, there are two main challenges dealing with scientific data management. As a recent paper showed, one big problem is the data loss: 80% of scientific data got lost within 20 years due to technological progress in storage or elderly of communication network (mainly old email address of authors). The other one is the so-called data tsunami, that occurs when a small number of data is re-used somehow. This process can generate a large amount of other data that, repeated thousands of times, becomes hardly manageable in terms of storage, accessibility and use. To avoid these two problem, Horizon 2020 is building up three general tools: the Data Management Plans, the e-Infrastructures research and the Open Access policy.
Data Management Plan (DMP)
First of all, the Data Management Plan (DMP – here the H2020 guide to Data Management) is a document that “describes the data management life cycle for all data sets that will be collected, processed or generated by the research project,... even after the project is completed”. This kind of document is compulsory for those projects participating in the Pilot Action on Open Research Data (see the Guidelines on Open Access to Scientific Publications and Research Data in Horizon 2020).
The Pilot action is aimed to improve and maximise access to and re-use of research data generated by projects. “Future and emerging technologies”, “Research infrastructures”, “Leadership in enabling and industrial technologies”, “Secure, Clean and Efficient Energy”, 'Climate Action, Environment, Resource Efficiency and Raw materials” (except raw materials), “Europe in a changing world” and “Science with and for Society” are the areas that will participate in the Pilot Action in the workprogram 2014-2015.
Out of the Pilot Action, even other projects are strongly invited to produce a DMP, whether relevant or suitable for their research.
A DMP must be submitted within 6 months, and can be implemented during all the life cycle of the research.
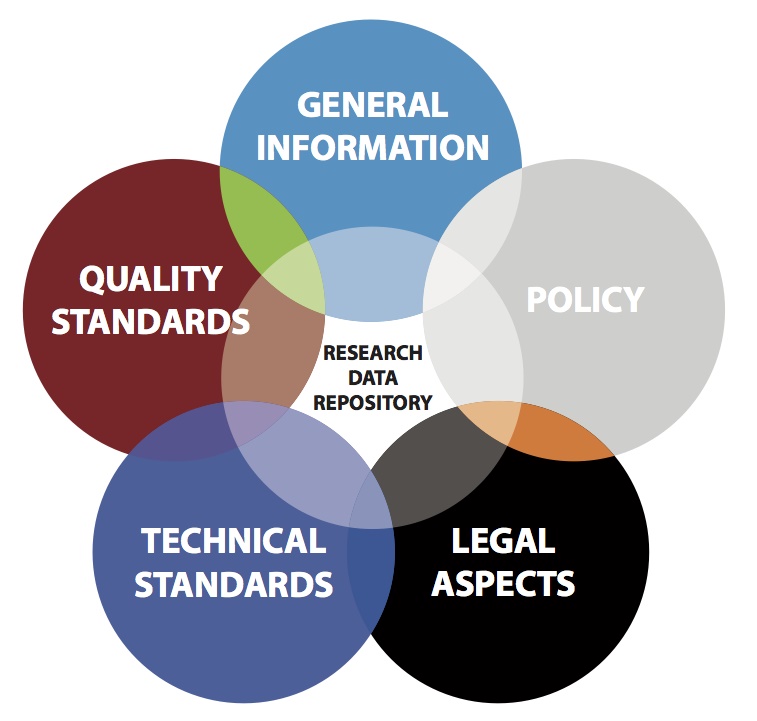
Figure 1 – Aspects of a Research Data Repository (Source)
E-Infrastuctures for Research Data
This (see the Framework of action on the issue) is one of the issue in which Horizon 2020 will invest more against data tsunami or data loose. Building up e-Infrastructures for scientific data has two meanings. First, it is meant to standardize the enormous heterogeneity and fragmentation of data from different fields of study or sources. Then it has an economic aspect. E-Infrastructures can lead to a scale-economy, which means that science-related enterprises can undergo lower costs to find data they need.
Some kinds of e-Infrastructures already exist, but they are too chaotic. To simplify the environment, H2020 developed a conceptual framework of “fiches”, that means “concrete domains of action”. These fiches are seven:
- Fiche 1: software to mash-up data from different sources exploring multidisciplinary knowledge
- Fiche 2: opening access to knowledge through reliable, distributed and participatory data e-infrastructures
- Fiche 3: cost effective infrastructures for preservation and curation for re-use of data that may be unique or very costly to replicate and coping with exascale volumes and complexity
- Fiche 4: e-infrastructures for persistent availability of information and linking people and data through flexible and robust digital identifiers
- Fiche 5: establish the interoperability layer for consistency of approaches on global data exchange (in domains like climate modelling, biodiversity, genomics, astronomy, high energy physics, social sciences, etc).
- Fiche 6: enabling trust through Authentication and Authorisation platforms that scholars and researchers can use to implement the Open Access policies taking into account privacy or other type of restrictions
- Fiche 7: developing skills of users and producers of data to ensure a reliable “data life-cycle”
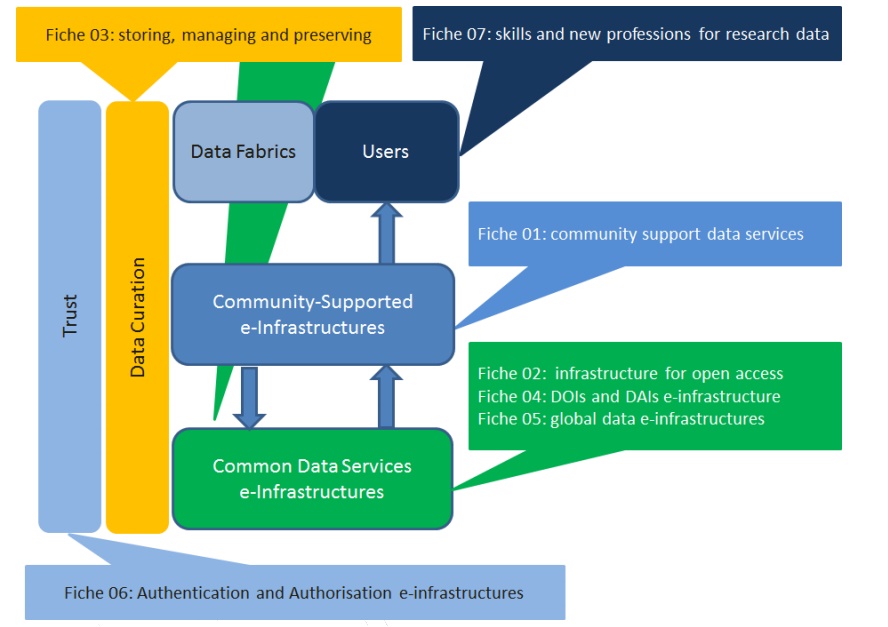
Figure 2 – Fiches in the e-Infrastructures framework of H2020 (Source)
Open Access
The Open Access option about scientific research data is strongly debated, mainly referring to the problem of patenting scientific outputs. This had been deeply considered in setting the open access policies for H2020.
Horizon 2020 defines the Open Access through two main goals, namely that data are free of charge and re-usable. Moreover, H2020 sets a general principle for managing the open access issue:
“open access requirements in no way imply an obligation to publish results. The decision on whether or not to publish lies entirely with the fundees. Open access becomes an issue only if publication is elected as a means of dissemination... [and] does not interfere with the decision to exploit research results commercially, e.g. through patenting. Indeed, the decision on whether to publish open access must come after the more general decision on whether to publish directly or to first seek protection.”
According to the way the scientific results are published, H2020 distinguish between gold open access, when it deals with open access publishing, or green open access, when it deals with self-archiving.
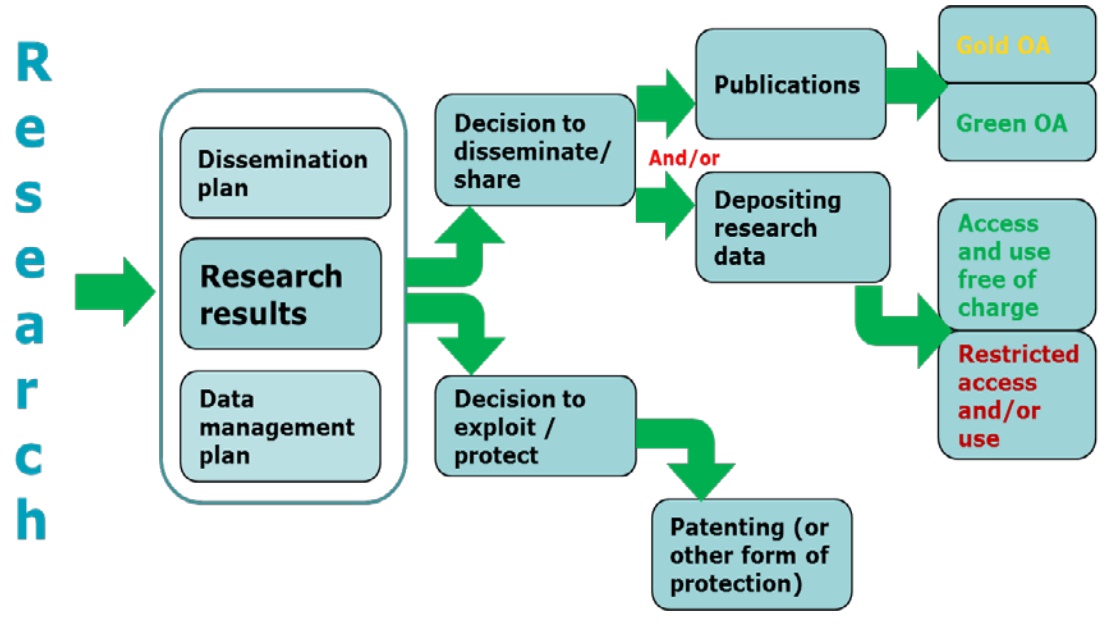
Figure 3 – Options in open access and dissemination of data in H2020 (Source)
The reasons why H2020 is pushing a lot on open access are basically four, all related to foster scientific research to the highest standard and to maximize the efficiency of the public spending of money. Open access, in the H2020 meanings, will improve:
- Quality of research, by rooting into previous researches.
- Efficiency, by avoiding replication of data
- Innovation, by fastering the access to market
- Transparency, by involving citizens into the scientific process
This is the conceptual framework of open access in H2020. But how will it be in concrete? The article 29.2 of the Model Grant Agreement says expressly that:
“The beneficiary must ensure open access (free of charge, online access for any user) to all peer-reviewed scientific publications relating to its results. In particular, it must:
(a) as soon as possible and at the latest on publication, deposit a machine-readable electronic copy of the published version or final peer-reviewed manuscript accepted for publication in a repository for scientific publications. Moreover, the beneficiary must aim to deposit at the same time the research data needed to validate the results presented in the deposited scientific publications.
(b) ensure open access to the deposited publication — via the repository — at the latest:
- on publication, if an electronic version is available for free via the publisher, or
- within six months of publication (twelve months for publications in the social sciences and humanities) in any other case.
(c) ensure open access — via the repository — to the bibliographic metadata that identify the deposited publication, which must include a persistent identifier.”
