
Un sistema per determinare la fascia di disposizione regionali per il contenimento della diffusione dell’epidemia da Covid 19 deve essere un sistema:
- di semplice calcolo,
- riproducibile da chiunque con semplicità,
- creato adottando i dati pubblicati ufficialmente.
Seguendo queste indicazioni è stata elaborata questa proposta di algoritmo sperando che venga presa in considerazione.
Le ragioni della proposta
L’operazione di assegnare a ogni Regione un “colore” associato a una serie di disposizione finalizzate al contenimento della diffusione dell’epidemia si giustifica con il tentativo di modulare i disagi per l’economia e le relazioni sociali ai livelli di rischio di contagio presenti in ciascuna Regione.
Si può ritenere che i tempi di trasmissione del contagio siano di circa 7-10 giorni da un soggetto a un altro e che i tempi di diagnosi e notifica siano di ulteriori 3-5 giorni, per cui mediamente si può ritenere che i soggetti che vengono comunicati come positivi giornalmente dal Ministero si siano in realtà contagiati all’incirca due settimane prima.
Le misure di contenimento predisposte per un determinato giorno produrranno quindi i loro effetti positivi non prima di due settimane e quindi la valutazione dell’intensità del rischio di contagio non deve riguardare l’oggi bensì la stima relativa a due settimane successive.
Come operare questa stima? Si può calcolare lo sviluppo probabile dei casi positivi in assenza di nuove misure di contenimento moltiplicando l’incidenza odierna per il valore dell’indice di replicazione diagnostica a sette giorni per due volte successive, cioè se l’incidenza odierna fosse 100 e nell’ultima settimana fosse aumentata del 50% si può ritenere che tra due settimane sarà probabilmente di [100 x 1,5 x 1,5], cioè 225.
L’incidenza di un giorno è bene calcolarla come la media dei nuovi casi di sette giorni, cioè l’attuale più i sei precedenti, così evitando gli sbalzi della variabilità intra settimanale, e dividendola per la popolazione residente; viene poi riferita solitamente a mille abitanti.
L’indice di replicazione diagnostica invece può essere facilmente calcolato come rapporto tra l’incidenza prima indicata e quella dei sette giorni ancora precedenti a quelli su cui la prima è stata calcolata (si veda "Rt or RDt, that is the question!", pubblicato su Epidemiologia e prevenzione).
Quindi, facendo un esempio, se due Regioni hanno la prima incidenza 40 e la seconda 60, e indice di replicazione diagnostica, la prima pari a 1,5 e la seconda pari a 0,5, la stima dell’incidenza probabile a due settimane sarà per la prima 90 [40 x 1,5 x 1,5] e per la seconda 15 [ 60 x 0,5 x 0,5]. Se si usasse come cut off per definire una zona come rossa il valore 50, allora usando il dato odierno la si applicherebbe inutilmente alla seconda che già di per se sta decrescendo e si lascerebbe invece crescere indisturbatamente la prima, facendo così un grave errore.
La stima dell'incidenza utilizza la frequenza dei nuovi casi con esito positivo al test molecolare; ma questi test non vengono ovunque effettuati con la stessa strategia e in particolare mentre facilmente vengono effettuati ovunque similmente per i contagiati con evidente sintomatologia non lo sono per pauci o per gli a-sintomatici. È allora opportuno introdurre una correzione dell’incidenza stimata utilizzando i dati dei decessi. Si calcola allora come valore convenzionale della letalità il rapporto tra i decessi dell’ultima settimana con i casi positivi di due settimane precedenti, in base all’ipotesi che la latenza media tra notifica di positività e notifica di decesso si aggiri sulle due settimane.
La correzione da introdurre può allora essere calcolata come rapporto tra la letalità così calcolata per ogni Regione e la letalità dell’intera nazione. Se la letalità è maggiore si possono ipotizzare due motivi, e cioè o che al denominatore ci siano meno soggetti perché asintomatici non diagnosticati o perché al numeratore vi siano più deceduti dovuti alla maggiore gravità delle patologie ovvero alla maggiore suscettibilità della popolazione, dovuta ad esempio alla loro maggiore età media. In tutti questi casi risulta opportuno correggere in più o in meno la incidenza probabile stimata.
Stabilita in modo “oggettivo” l’incidenza probabile a due settimane, sarà poi la politica a stabilire i valori soglia che definiscono il “colore” delle Regioni in funzione appunto dei valori risultanti e che possono venir aggiornati anche giornalmente o alle scadenze che si ritengono opportune allo scopo di rivalutare appunto i “colori”.
Descrizione della proposta
Si propone quindi di moltiplicare l’incidenza media della settimana passata per l’indice di replicazione diagnostica che rappresenta l’evoluzione attuale dell’incidenza applicando poi una ulteriore correzione basata sui dati dei decessi consistente nel correggere l’incidenza futura probabile per il rapporto tra la letalità della Regione e la letalità nazionale.
Questi i dati considerati:
CUS = casi ultima settimana
CSP = casi settimana precedente
CDP = casi di due settimane precedenti
DUS = decessi ultima settimana
POP = popolazione residente
Queste le variabili considerate:
IUS = incidenza giornaliera media ultima settimana = CUS X 100.000 / RES / 7
RDt = indice di Replicazione Diagnostica a lag 7 = CUS / CSP
LET = letalità = DUS X 100 / CDP
LER = letalità relativa = LET (regione) / LET (italia)
Questi gli indici calcolabili:
INP = incidenza probabile a due settimane = IUS X RDt X RDt
INC = incidenza probabile corretta = INP X LER
Questi i calcoli al 31 dicembre 2020:
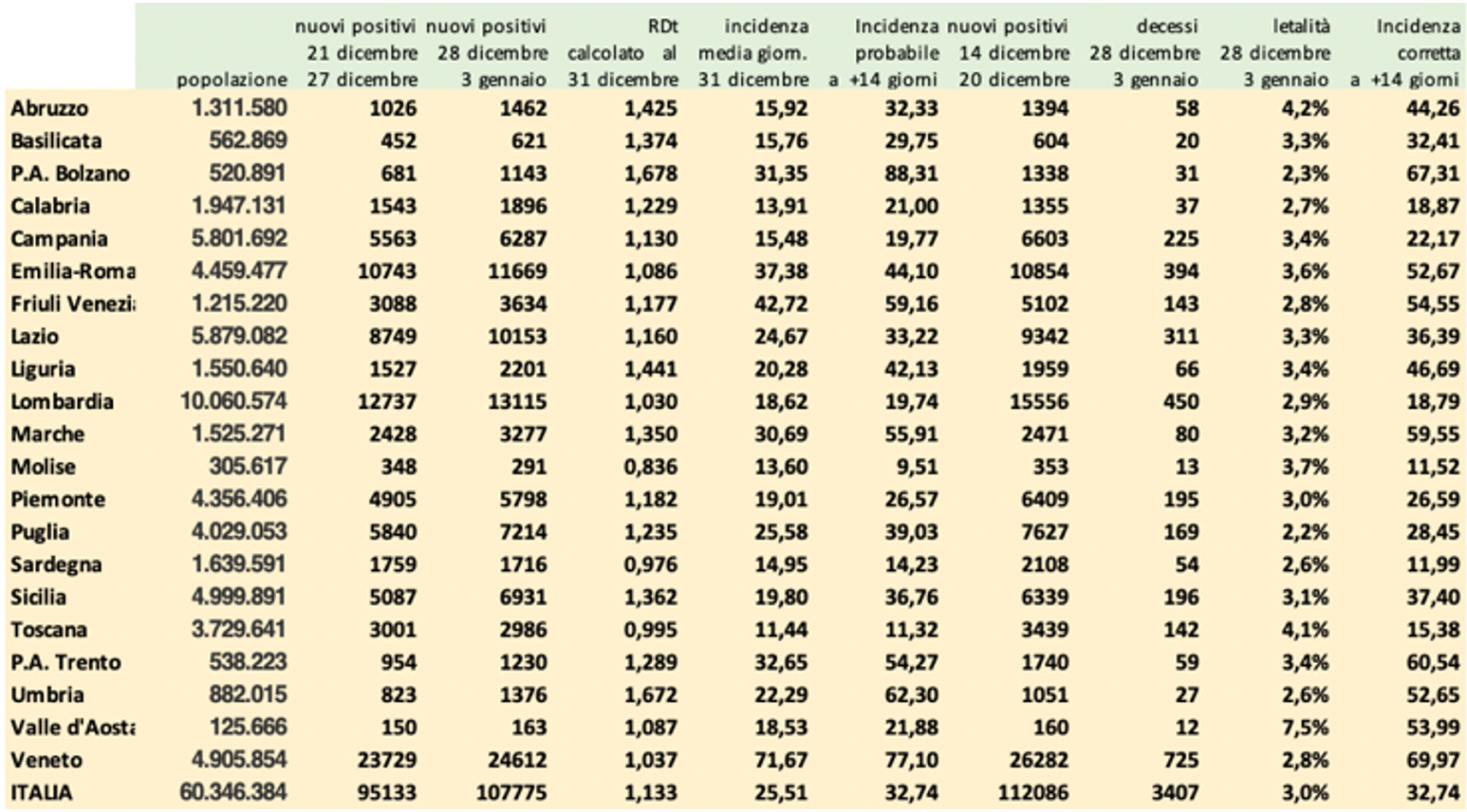
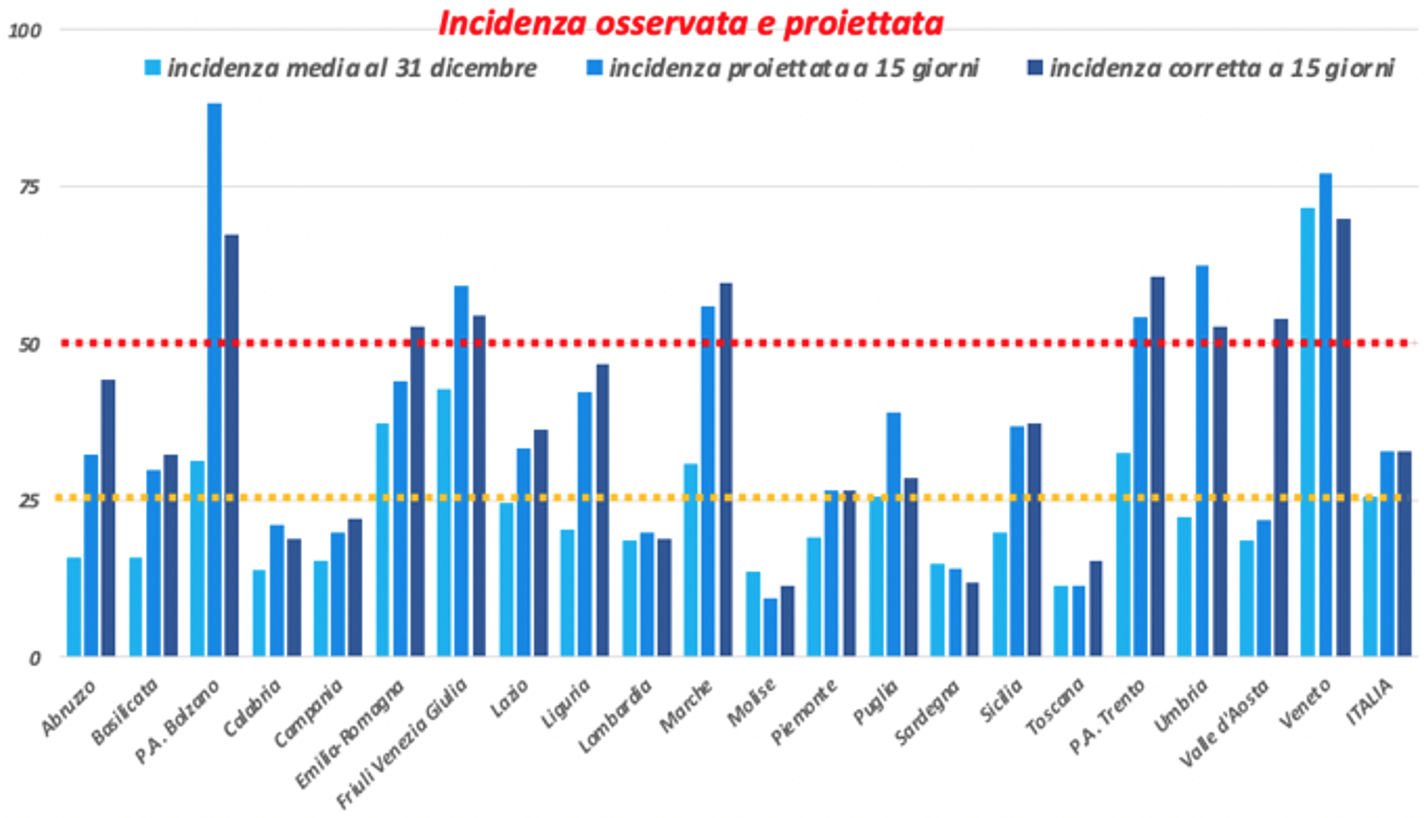
I valori di IPC in ciascuna Regione potranno guidare la politica nell’assegnazione ad una delle aree di rischio, definite da un codice colore, adottando delle fasce che, a titolo semplicemente esemplificativo, potrebbero essere simili alle seguenti:
IPC < 12,5 = area BIANCA
12,5 ≤ IPC < 25 = area GIALLA
25 ≤ IPC < 50 = area ARANCIONE
IPC > 50 = area ROSSA
Confidiamo che questa proposta possa esser attentamente valutata dal Governo e dalle Regioni poiché riteniamo che potrebbe rendere più adeguata, più oggettiva e più trasparente la metodologia per l’assegnazione di ciascuna Regione ad una area di rischio.
Nota
Questo algoritmo è proposto da Cesare Cislaghi, rivisto da Andrea Messori e Daniela Celin e ridiscusso coi partecipanti al Blog Sanità su Messenger di Facebook.
